1 - Introduction to MS2extract
Cristian Quiroz-Moreno & Jessica Cooperstone
2023-08-26
Source:vignettes/1_introduction.Rmd
1_introduction.RmdIntroduction
This vignette has the objective to introduce the MS2extract. The main goal of this package is to provide a tool to create in-house MS2 compound libraries. Users can access a specific function help through the command help([‘function name’]). It is worth to note that this package is aimed in the targeted extraction of MS/MS scans and it is not able to perform compound matching/annotation.
A simplified workflow is presented in Figure 1. Briefly, mzXML files are imported in memory, then based on metadata provided by the user such as compound chemical formula, and the theoretical precursor m/z based on the chemical formula provided by the user in the metadata.Then, product ion scans are extracted with a given ppm tolerance. Next, low intensity signals, or background noise, can be removed from the spectra. Finally, users can export the extracted MS/MS spectra to a msp file format to be used as reference library for further compound identification and annotation.
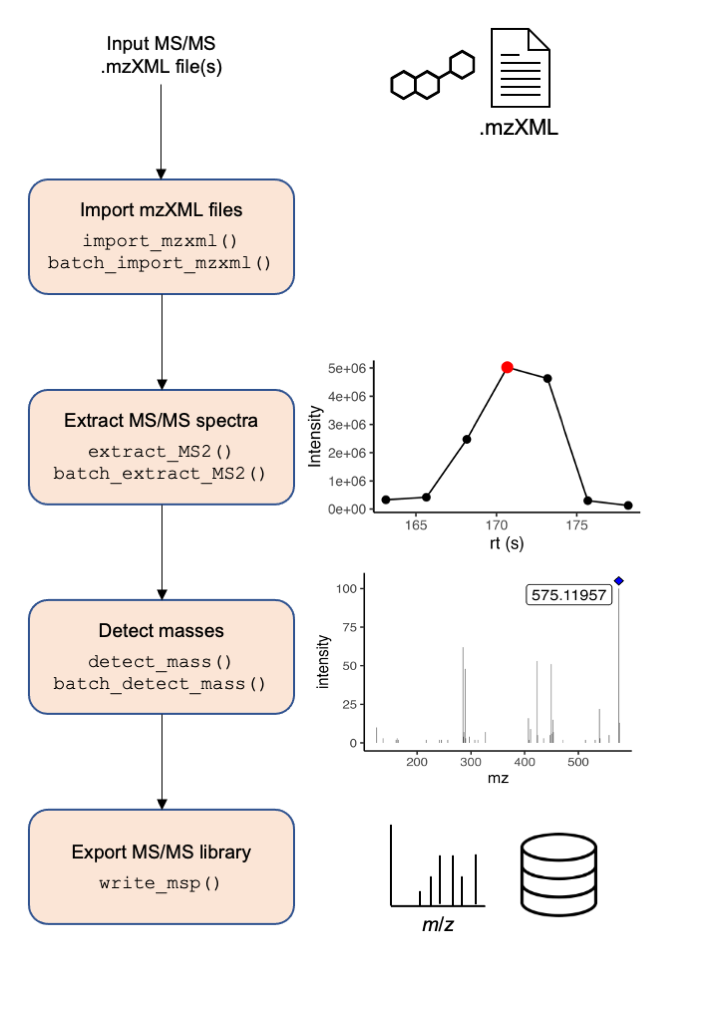
Figure 1. Overview of the processing pipeline to extract MS/MS spectra using the MS2extract package
Basic workflow
The MS2 workflow has four main steps:
- data import,
- extract MS/MS scans,
- detect masses, and
- export MS/MS library
In this section, we will explain in a more detail the main steps, as well as provide information about the required and optional arguments that users may need to provide in order to effectively use this package.
Additionally, this package also includes a set of
batch_*() functions that allows to process multiple .mzXML
files at once. However, more metadata is required to run this automated
pipeline and the use of this batch_*() functions will is
described in the Using
MS2extract Batch Pipeline.
Data import
This section is focused on describing how MS2extract package imports MS/MS data.
The main import function relies on R package metID. We adapted the import function in order to read mass spectrometry data from mzXML files. The new adaptation consists in importing scans data in a list (S3 object) rather than into a S4 object, facilitating the downstream tidy analysis of this object.
This function execute a back-end calculation of theoretical ionized m/z of the compound in order to extract the precursor ions that match that mass with a given ppm.
The arguments of the import_mzxml() functions are
four:
- file
- met_metadata
- ppm
- …
# Loading the package
library(MS2extract)
# Print function arg
formals(import_mzxml)
#> $file
#> NULL
#>
#> $met_metadata
#> NULL
#>
#> $ppm
#> [1] 10
#>
#> $...file
File should contain the name of your .mzXML file that contains MS/MS data of authentic standards or reference material. Here, we provide an example file of procyanidin A2 collected in negative ionization mode with a collision energy of 20 eV.
# Importing Procyanidin A2 MS/MS spectra in negative ionization mode
# and 20 eV as the collision energy
ProcA2_file <- system.file("extdata",
"ProcyanidinA2_neg_20eV.mzXML",
package = "MS2extract"
)
# File name
ProcA2_file
#> [1] "/home/runner/work/_temp/Library/MS2extract/extdata/ProcyanidinA2_neg_20eV.mzXML"met_metadata
This argument refers to the compound metadata that user need to provide in order to properly import scans that are related to the compound of interest.
The met_metadata is a data frame that has required and
optional columns. The required columns are employed to calculate the
theoretical ionized m/z for a given formula and
ionization mode. In the optional columns, we have the option to provide
a chromatographic Region Of Interest (ROI) specifying where the the
compound elutes in order to only keep this rentention time window.
The required columns are:
- Formula: A character string specifying the metabolite formula
- Ionization_mode: The ionization mode employed in data collection.
The optional columns are:
- min_rt: a double with the minimum retention time to keep (in seconds)
- max_rt: a double with the minimum retention time to keep (in seconds)
# Procyanidin A2 metadata
ProcA2_data <- data.frame(
Formula = "C30H24O12", Ionization_mode = "Negative",
min_rt = 163, max_rt = 180
)
ProcA2_data
#> Formula Ionization_mode min_rt max_rt
#> 1 C30H24O12 Negative 163 180ppm
ppm refers to the maximum m/z deviation from the theoretical mass. A ppm of 10 units will mean that the total allows m/z window in 20 ppm since. By default, 10 ppm is used.
import_mzxml()
With all arguments explained, we can use the
import_mzxml() function.
# Import Procyanidin A2 data
ProcA2_raw <- import_mzxml(ProcA2_file, met_metadata = ProcA2_data, ppm = 5)
#> Reading MS2 data from ProcyanidinA2_neg_20eV.mzXML
#> Processing...
# 24249 rows = ions detected
dim(ProcA2_raw)
#> [1] 24249 4Extracting MS/MS spectra
Now that we have the data imported, we can proceed to extract the most intense MS/MS scan of all scans.
This function computes the MS/MS Total Ion Chromatogram (TIC) by summing up all intensities of the MS/MS spectra and selects the scan with the highest intensity.
This function takes three arguments:
- spec: the imported MS/MS spectra
-
verbose: a boolean, if
verbose = TRUE, the MS/MS TIC and spectra is printed, ifverbose = FALSE, plots are not displayed -
out_list: a boolean, if
out_list = TRUE, the extracted MS/MS spectra table and plots are returned as list, otherwise only the MS/MS spectra is returned as data frame.
ProcA2_extracted <- extract_MS2(ProcA2_raw, verbose = TRUE, out_list = FALSE)
#> Warning: `position_stack()` requires non-overlapping x intervals
Here, we can see in the top plot of the MS2 TIC that the scan colored in red is the most intense and the one for which the MS/MS spectra will be exported (at 170.667 s). In the bottom plot, we can see the procyanidin A2 MS/MS spectra at rt: 170.667.] The maximum m/z axis value is > 1500 m/z but not significant ions are displayed. This can be explained due to low intensities are kept in the MS/MS spectra.
range(ProcA2_extracted$mz)
#> [1] 100.0852 1699.0981The range of the MS/MS m/z values are from 100 to 1699 m/z, but intensities are too low to be seen in the plot.
Detecting masses
Similarly to the MZmine pipeline, detecting masses refers to set a minimum signal intensity threshold value that product ions have to meet in order to be kept in the data. This function can also normalize the spectra ion intensity to percentage based on the base peak. This is a filtering step that is based on percentage ofthe base peak (most intense ion).
The three required arguments are:
- spec: a data frame containing the MS2 spectra.
- normalize: a boolean indicating if the MS2 spectra is normalized by the base peak before proceeding to filter out low intensity signals (normalize = TRUE), if normalize = FALSE the user has to provide the minimum ion count.
- min_int: an integer referring to the minimum ion intensity. The value of min_int has to be in line if user decides to normalize the spectra or not. If the spectra is normalized, the min_intensity value is in percentage, otherwise the min_intensity value is expressed in ion count units.
By default, the normalization is set to TRUE and the
minimum intensity is set to 1% to remove background noise.
ProcA2_detected <- detect_mass(ProcA2_extracted, normalize = TRUE, min_int = 1)We can see now the range of m/z values and the maximum value is 576.1221 m/z.
range(ProcA2_detected$mz)
#> [1] 125.0243 576.1221MS/MS spectra plot
We can proceed to plot the filtered MS/MS spectra with
plot_MS2spectra() function. This is a ggplot2 based
function; the blue diamond refers to the precursor ion.
If we take a look to the previous MS/MS plot, there is less background noise in this MS/MS spectra because the low intensity ions have been removed.
plot_MS2spectra(ProcA2_detected)
#> Warning: `position_stack()` requires non-overlapping x intervals
Exporting MS/MS spectra
Finally after extracting the MS/MS spectra and removing background noise, we can proceed to export the MS2 in a .msp format.
For this task, we need extra information about the compound, such as SMILES, COLLISIONENERGY, etc.
An example of this table can be found at:
# Reading the metadata
metadata_file <- system.file("extdata",
"msp_metadata.csv",
package = "MS2extract"
)
metadata <- read.csv(metadata_file)
dplyr::glimpse(metadata)
#> Rows: 1
#> Columns: 8
#> $ NAME <chr> "Procyanidin A2"
#> $ PRECURSORTYPE <chr> "[M-H]-"
#> $ FORMULA <chr> "C30H24O12"
#> $ INCHIKEY <chr> "NSEWTSAADLNHNH-LSBOWGMISA-N"
#> $ SMILES <chr> "C1C(C(OC2=C1C(=CC3=C2C4C(C(O3)(OC5=CC(=CC(=C45)O)O)C6…
#> $ IONMODE <chr> "Negative"
#> $ INSTRUMENTTYPE <chr> "LC-ESI-QTOF"
#> $ COLLISIONENERGY <chr> "20 eV"The precursor ion is not necessary to provide since this information is included in the extracted MS/MS spectra.
The three arguments for this function are:
- spec: a data frame containing the extracted MS2 spectra
- spec_metadata: a data frame containing the values to be including in the resulting .msp file
- msp_name: a string with the name of the msp file not containing (.msp) extension
write_msp(
spec = ProcA2_detected,
spec_metadata = metadata,
msp_name = "Procyanidin_A2"
)After writing the msp file, you will see the following file content:
#> NAME: Procyanidin A2
#> PRECURSORMZ: 575.11957
#> PRECURSORTYPE: [M-H]-
#> FORMULA: C30H24O12
#> RETENTIONTIME: 2.844
#> IONMODE: Negative
#> COMMENT: Spectra extracted with MS2extract R package
#> INCHIKEY: NSEWTSAADLNHNH-LSBOWGMISA-N
#> SMILES: C1C(C(OC2=C1C(=CC3=C2C4C(C(O3)(OC5=CC(=CC(=C45)O)O)C6=CC(=C(C=C6)O)O)O)O)C7=CC(=C(C=C7)O)O)O
#> CCS:
#> COLLISIONENERGY: 20 eV
#> INSTRUMENTTYPE: LC-ESI-QTOF
#> Num Peaks: 38
#> 125.02431 10
#> 137.02441 3
#> 161.02449 2
#> 163.00355 3
#> 165.01881 2
#> 217.04996 2
#> 241.05002 2
#> 245.04547 2
#> 245.0817 2
#> 257.0451 2
#> 285.04063 62
#> 286.04387 4
#> 287.05579 7
#> 289.0718 48
#> 290.07495 3
#> 297.03993 4
#> 307.06114 2
#> 313.03573 2
#> 327.05044 7
#> 407.07693 16
#> 408.08161 2
#> 411.07227 9
#> 423.07231 53
#> 424.07537 5
#> 435.07138 3
#> 447.07296 5
#> 449.08799 51
#> 450.09044 6
#> 452.07453 15
#> 453.08155 7
#> 471.1086 2
#> 513.11796 2
#> 531.13006 2
#> 539.09834 22
#> 540.10156 3
#> 557.10809 5
#> 575.11968 100
#> 576.12208 13Session info
sessionInfo()
#> R version 4.3.1 (2023-06-16)
#> Platform: x86_64-pc-linux-gnu (64-bit)
#> Running under: Ubuntu 22.04.3 LTS
#>
#> Matrix products: default
#> BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
#> LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.20.so; LAPACK version 3.10.0
#>
#> locale:
#> [1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
#> [4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
#> [7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
#> [10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
#>
#> time zone: UTC
#> tzcode source: system (glibc)
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] MS2extract_0.01.0
#>
#> loaded via a namespace (and not attached):
#> [1] tidyselect_1.2.0 farver_2.1.1 dplyr_1.1.2
#> [4] fastmap_1.1.1 XML_3.99-0.14 digest_0.6.33
#> [7] lifecycle_1.0.3 cluster_2.1.4 ProtGenerics_1.32.0
#> [10] magrittr_2.0.3 compiler_4.3.1 rlang_1.1.1
#> [13] sass_0.4.7 tools_4.3.1 utf8_1.2.3
#> [16] yaml_2.3.7 knitr_1.43 ggsignif_0.6.4
#> [19] labeling_0.4.2 plyr_1.8.8 abind_1.4-5
#> [22] BiocParallel_1.34.2 withr_2.5.0 purrr_1.0.2
#> [25] BiocGenerics_0.46.0 desc_1.4.2 grid_4.3.1
#> [28] stats4_4.3.1 preprocessCore_1.62.1 fansi_1.0.4
#> [31] ggpubr_0.6.0 colorspace_2.1-0 ggplot2_3.4.3
#> [34] scales_1.2.1 iterators_1.0.14 MASS_7.3-60
#> [37] cli_3.6.1 crayon_1.5.2 mzR_2.34.1
#> [40] rmarkdown_2.24 ragg_1.2.5 generics_0.1.3
#> [43] Rdisop_1.60.0 ncdf4_1.21 cachem_1.0.8
#> [46] affy_1.78.2 stringr_1.5.0 zlibbioc_1.46.0
#> [49] parallel_4.3.1 impute_1.74.1 BiocManager_1.30.22
#> [52] vsn_3.68.0 vctrs_0.6.3 carData_3.0-5
#> [55] jsonlite_1.8.7 car_3.1-2 IRanges_2.34.1
#> [58] S4Vectors_0.38.1 ggrepel_0.9.3 MALDIquant_1.22.1
#> [61] rstatix_0.7.2 clue_0.3-64 systemfonts_1.0.4
#> [64] foreach_1.5.2 limma_3.56.2 tidyr_1.3.0
#> [67] jquerylib_0.1.4 affyio_1.70.0 glue_1.6.2
#> [70] MSnbase_2.26.0 pkgdown_2.0.7 codetools_0.2-19
#> [73] cowplot_1.1.1 stringi_1.7.12 gtable_0.3.4
#> [76] OrgMassSpecR_0.5-3 mzID_1.38.0 munsell_0.5.0
#> [79] tibble_3.2.1 pillar_1.9.0 pcaMethods_1.92.0
#> [82] htmltools_0.5.6 R6_2.5.1 textshaping_0.3.6
#> [85] doParallel_1.0.17 rprojroot_2.0.3 evaluate_0.21
#> [88] lattice_0.21-8 Biobase_2.60.0 highr_0.10
#> [91] backports_1.4.1 memoise_2.0.1 broom_1.0.5
#> [94] bslib_0.5.1 Rcpp_1.0.11 xfun_0.40
#> [97] MsCoreUtils_1.12.0 fs_1.6.3 pkgconfig_2.0.3